
Introduction
The team at Nous Research proudly presents tinker-atropos, our integration layer between the Tinker API and our Atropos reinforcement learning (RL) framework. We designed Atropos to be a fully decoupled environment service, separating concerns around trainer management, rollout collection, and environment setup into three distinct components.
Consequently, we found Tinker to be a perfect fit for this paradigm, providing easier management of the inference weights while remaining as close to a fully on-policy approach as possible. The goal of our integration layer was to enable any Atropos environment to plug into Tinker with minimal, if any, modifications needed. We hope this effort will introduce new Atropos users to the Tinker framework and allow Tinker users to immediately get started with Atropos environments. Through decoupling training, inference, and trajectory collection, we are able to present a seamless, easy-to-use integration layer between the Tinker API and the Atropos RL framework.
Technical Approach / Architecture Overview
To integrate with Tinker, we first required an inference layer that could communicate with the SamplingClient. Initially, our design included an update_weights endpoint because the inference layer lived in a separate file, but we have since combined them into a single, unified trainer and inference file that handles the weight updates internally.
To provide log-probabilities (logprobs) in the inference response, which are crucial for importance sampling (IS) loss calculations, we have a pattern in Atropos environments called the ManagedServer. The ManagedServer allows for chat/completion responses while tracking logprobs over multiturn interactions for ease of integration in existing OpenAI harnesses.
We currently have the following Atropos environments configured to use this pattern:
- GSM8k
- AnswerFormat
- FundamentalPrediction (financial prediction)
- Instruction Following Algorithm
- Intern Bootcamp
- KernelBench
- Letter Counting
- MCQA Thinking
- Pydantic Schema Following
- Reasoning Gym
- RLAIF
- SWE RL
- Tool Calling
We started designing this integration layer with a few key goals:
- Leveraging the most minimal code possible.
- The trainer integration should be fully self-contained.
- No changes to existing Atropos environments should be needed (once the
ManagedServerpattern is applied). - The integration layer should be fully decoupled from both libraries’ codebases.
To begin building this integration, we needed a middle layer to abstract over our inference endpoints and communicate with the Tinker SamplingClient. Since Atropos environments directly call an inference API endpoint (e.g., SGLang or vLLM), we needed a way for this code path to utilize the sampling client without modifying the base environment code. As a result, our inference layer exposes OpenAI-compatible endpoints that can be called from the environment and communicate with the Tinker SamplingClient, which references our most current sampling weights.
We expose an API layer to Atropos that’s compatible with existing implementations. The ManagedServer in Atropos takes responses from both vLLM and SGLang calls and handles the formatting of the returned logprobs for use in IS loss calculation. We have been able to easily integrate any existing Atropos environment with the Tinker API through the tinker-atropos trainer, provided they follow this managed server pattern. Detailed instructions to implement new environments according to this pattern can be found in our README.
Experimental Setup
For our comparison between the frameworks and this integration layer, we chose to compare two identical runs: Tinker’s example training loop, rl_loop.py, and our example tinker-atropos training loop, located in trainer.py. We decided not to compare to the base Atropos example trainer, as it does not yet have LoRA support and thus would not provide an exact comparison. The same conversion prefixes and system prompts were used for each run we performed.
Below are the exact parameter configurations for both runs:
Model Configuration
- Base model: meta-llama/Llama-3.1-8B-Instruct
- LoRA rank: 32
- Learning rate: 4×10⁻⁵
- Optimizer: AdamW (β₁ = 0.9, β₂ = 0.95, ε = 1×10⁻⁸)
Training Configuration
- Loss function: Importance Sampling
- Number of training steps: 50
- Batch size: 128 total rollouts per step
- Group size: 16
- Max staleness: 3 steps
- Temperature: 1.0
- Max tokens: 256
Environment Configuration
- Dataset: GSM8k training set
- Dataset seeds: 42, 121212, 65432
- Reward structure: Binary (1.0 for correct, 0.0 for incorrect)
We averaged our results over the 3 data seeds for each framework, running training for 20 steps. The goal was to measure time per step, estimated cost, and logprob differences to measure performance across both implementations.
Results
Cost Comparison
We found that our runs, on average, cost about $0.06 more than the standard Tinker RL implementation for total tokens.
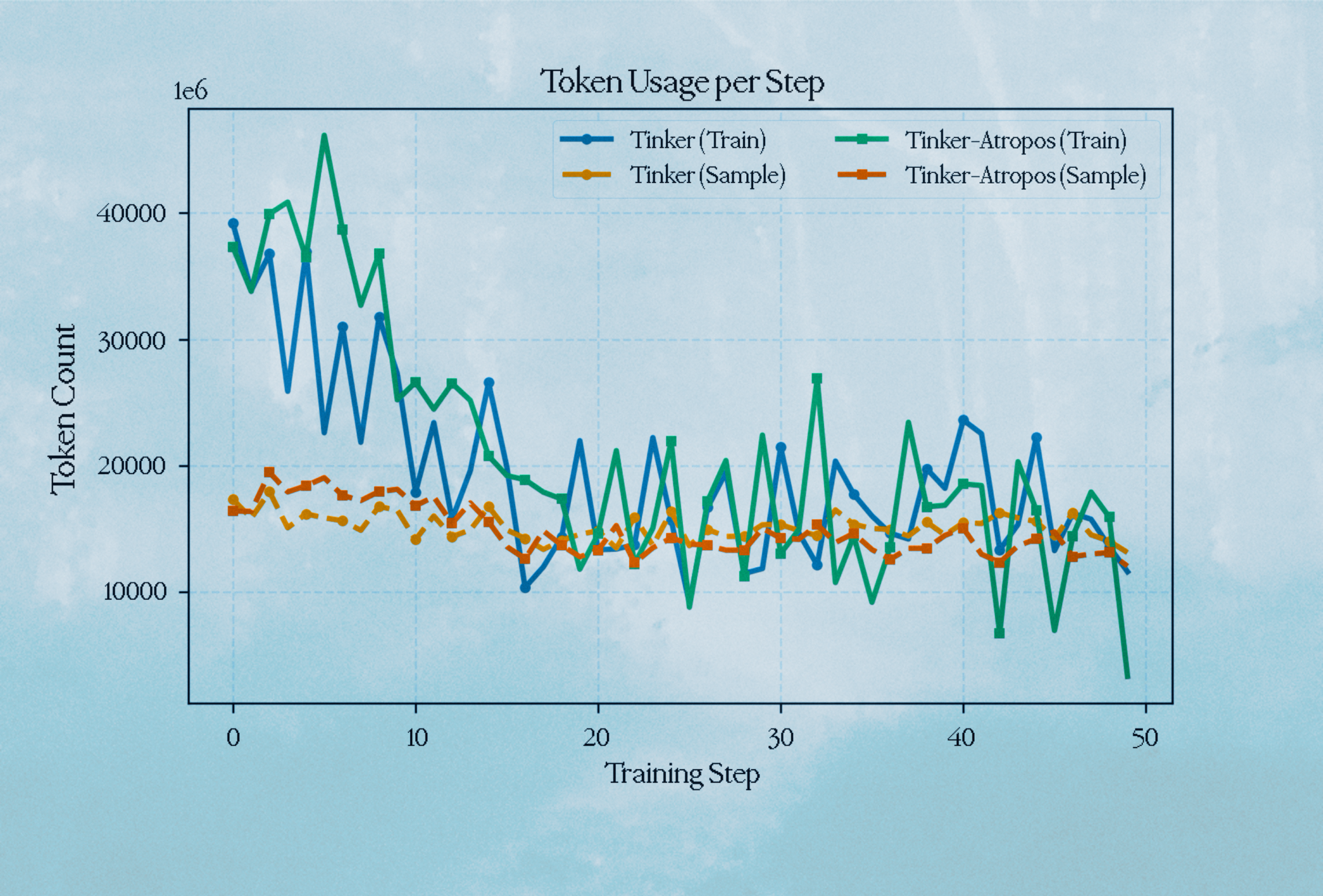
Token Usage
We present our token usage across both implementations for training and sampling tokens used.
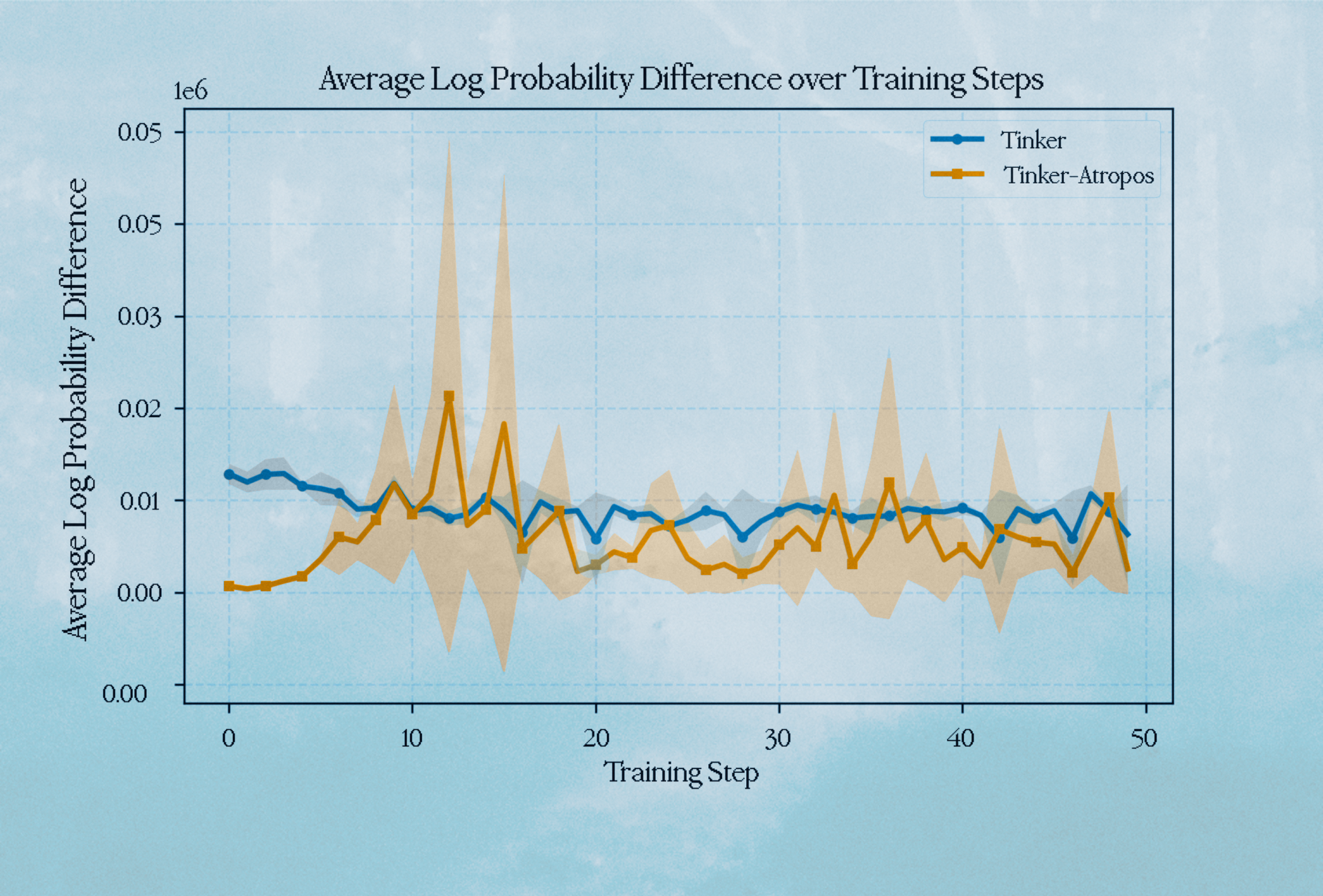
Average Logprob Difference
We illustrate the difference in training and inference logprobs between both implementations here, as a measure of how close to fully on-policy each implementation is.
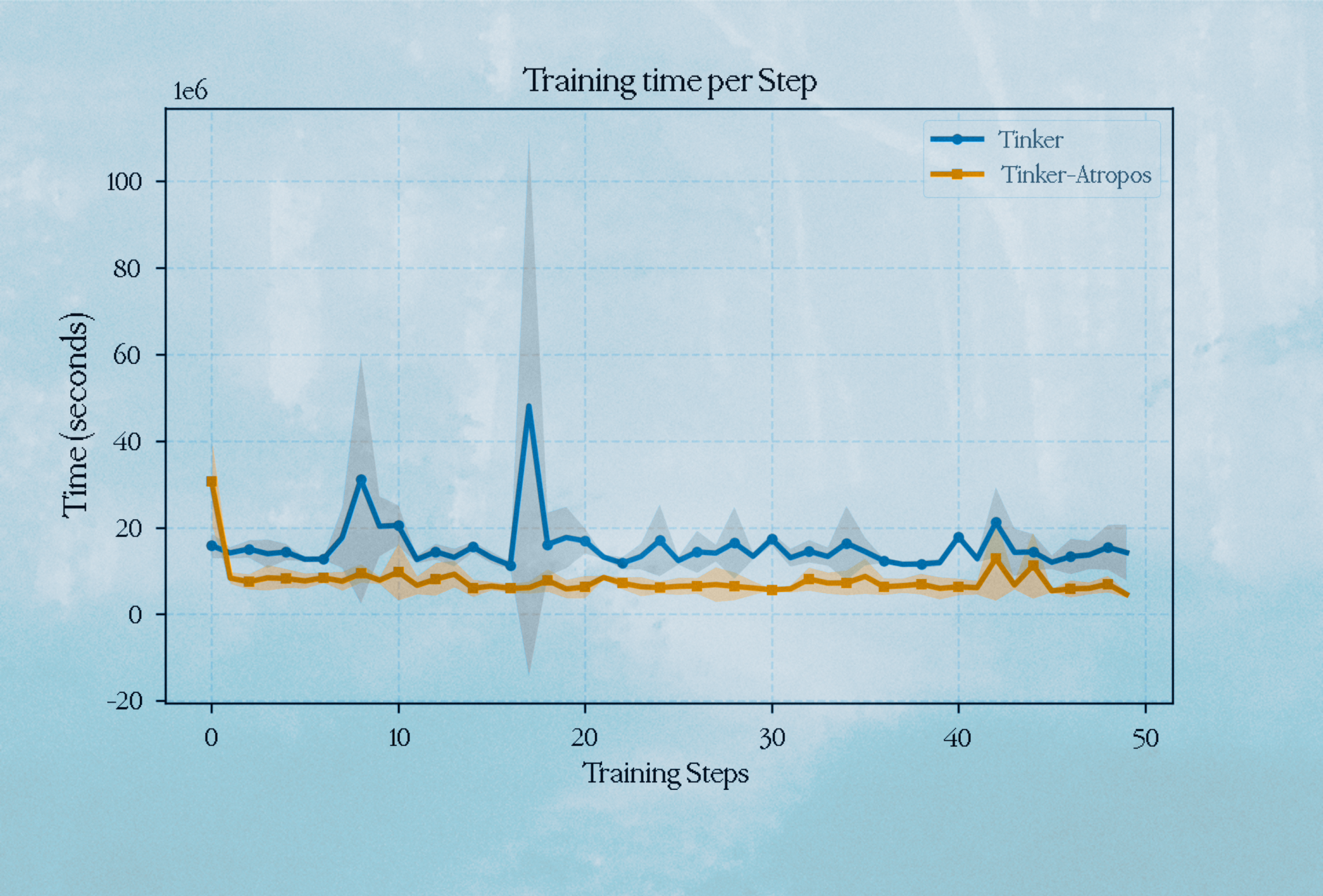
Training Time
We also compared the training time per step between both implementations and found that the Tinker-Atropos implementation had a lower average training time than the default Tinker implementation. This is likely due to how we structure our asynchronous RL: decoupled inference, environments, and training give us the ability to continually request inference while the forward/backward step is occurring.
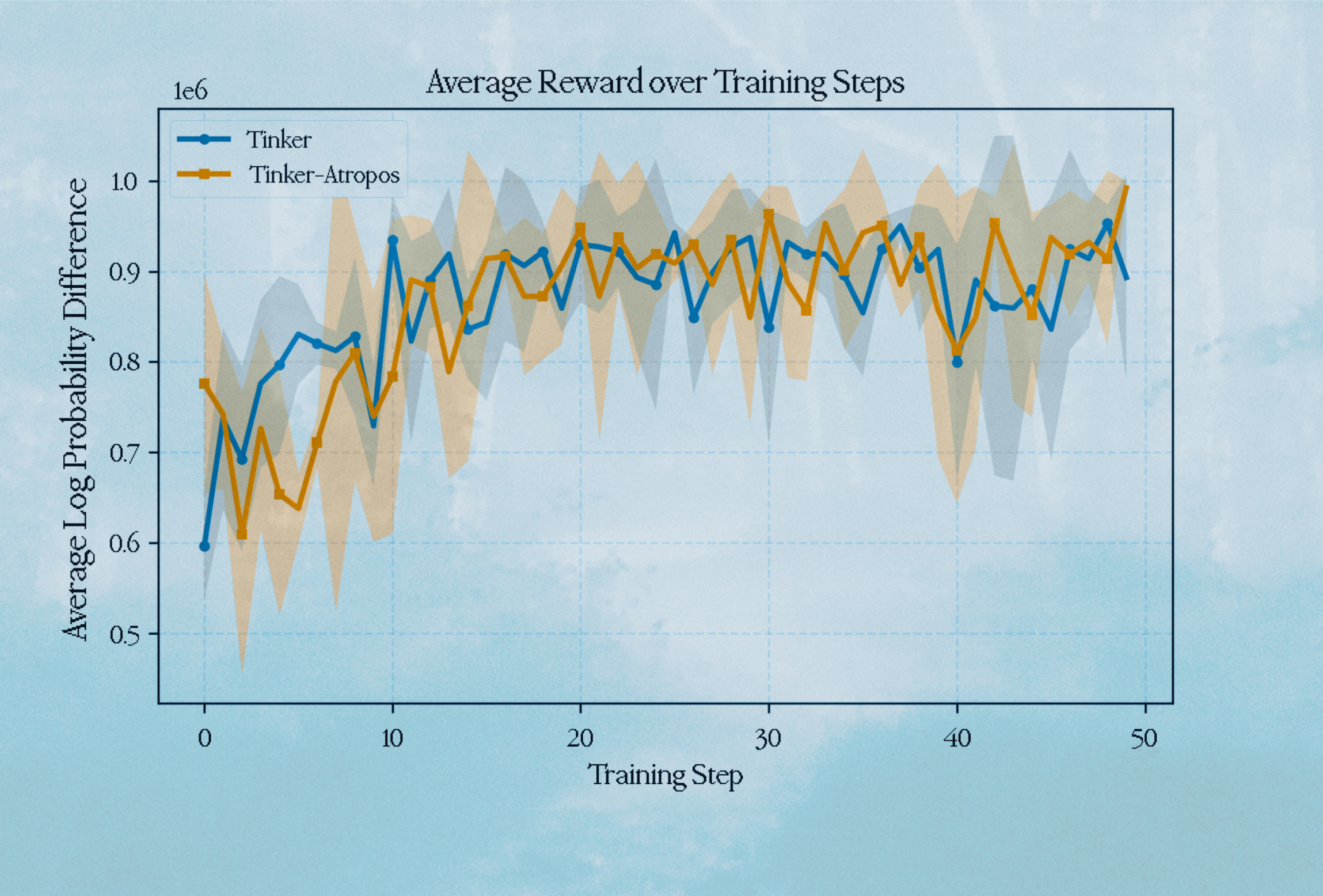
Average Reward per Step
We note that our average reward values approximately match the Tinker implementation over 50 steps.
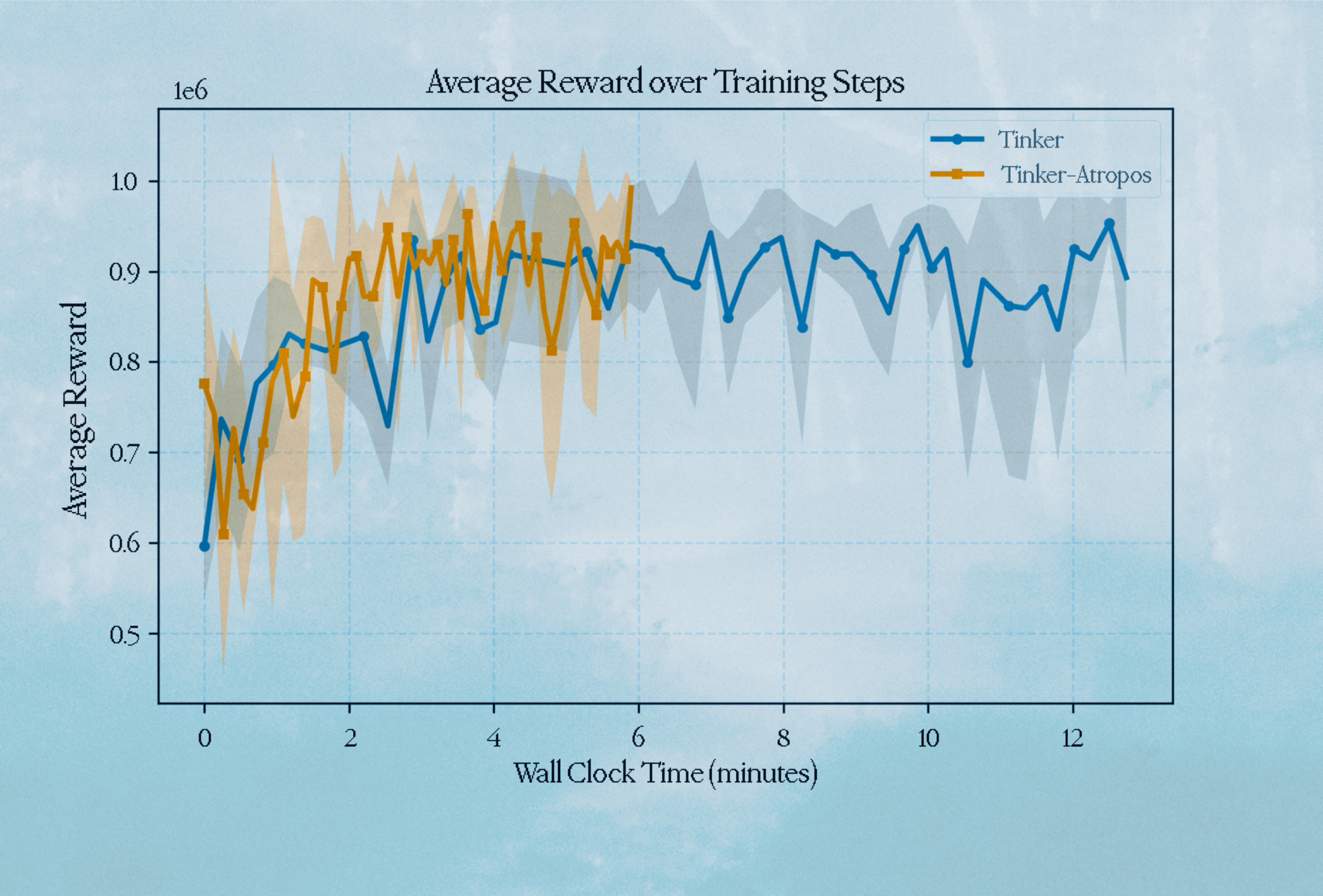
Average Reward over Wall Clock Time
We reach the plateau of 0.9 at 2 minutes compared to the 3 minutes it takes on the synchronous Tinker trainer.
Conclusion
To summarize our work, we have enjoyed testing the Tinker API and found it very simple to integrate with our existing reinforcement learning framework. We are excited to provide Atropos contributors with the ability to leverage a trainer-as-a-service framework through Tinker. This is used for testing integrations and running evals.
For integrating new environments with Tinker, we have detailed instructions in our project README, but the core principle relies mainly on using the ManagedServer pattern in any existing environment. The Atropos project also has instructions on how to create new environments to fit within the framework.
For future work, we would love to explore more features in Tinker, such as custom loss functions, PPO implementations, and on-policy distillation with the Atropos framework, and plan to continue developing this integration layer as both libraries gain more users and receive feedback. We want to extend our thanks to the team at Thinking Machines for their support throughout this development process, and we look forward to collaborating more in the future.