
Democratizing AI: The Psyche Network Architecture
INTRODUCTION
The development of advanced AI models has become increasingly centralized, requiring massive computational resources that only large corporations can afford. This concentration of power threatens innovation and limits who can contribute to AI progress, nearly guaranteeing that the systems built adhere to a closed entity's vision for "alignment." Meanwhile, enormous amounts of computing power sit idle or underutilized worldwide.
Psyche changes how we develop AI by creating a decentralized infrastructure that allows anyone to participate in training large language models. Rather than requiring massive infrastructure with thousands of accelerators in a single location, Psyche coordinates training across distributed, heterogeneous hardware worldwide.
The abundance of underutilized hardware, which grows daily, provides an opportunity to train and use LLMs without high investment costs.
The development roadmap consists of two main stages →
- 1 Cooperative Training Beginning with a permissioned testnet and transitioning toward a fully decentralized environment
- 2 Accessible Inference and Advanced Capabilities Including reinforcement learning and capabilities to create reasoning models
REFRESH ON DEMO/DISTRO
We first introduced our work on efficient decentralized training in DeMo: Decoupled Momentum Optimization . DisTrO built on those principal concepts to further improve performance. You can read a more complete explanation in the following blog post .
During LLM training, an optimizer dictates how to compute the gradient to update a model's parameters (AdamW is a well-known optimizer). In large setups, thousands of accelerators compute and share gradients (plus some extra information) among the entire network, so that each node gets a picture of what the other nodes learned during that training step.
DisTrO is a family of optimizers that leverages some unexpected properties of ML training to massively compress the information passed among accelerators.
The idea mimics the dynamics that underlie JPEG compression. When compressing an image, we translate a matrix (an MxN grid of pixels) into the frequency domain . Once translated to the frequency domain, many natural signals (sounds and images, for example) exhibit most of their information in the low-frequencies. This works because natural images change gradually across pixels — there are not often stark, hard edges in an image or recording. The big coefficients (the strongest waves) are typically at low frequencies (slow, smooth variations), and only small coefficients are at high frequencies (sharp, rapid changes). So, you can discard high frequencies without losing a ton of information, because the low frequencies tell you about the broader changes in the original matrix.

DeMo applies similar principles to AI training. Most optimizers track a "momentum tensor" - essentially a running average of past gradients, smoothing updates over time.
DeMo starts with Stochastic Gradient Descent with Momentum and decouples the momentum across the nodes, letting each node accumulate a unique momentum. We use the discrete cosine transform (DCT) to approximate an optimal translation into the frequency domain, because DCT is computationally cheap and accurate enough (JPEG compression uses the same). In the frequency domain, we extract the top k momentum components with the highest energy.
These momentum components are then communicated to each other node as a list of values and indices from which those values were extracted.
To keep our training from getting systematically biased over time, we had to change exactly how we compress information from typical JPEG compression schemes. In a typical JPEG compression scheme, high frequency components are consistently compressed more than low frequency components (because more information is expected in those low-frequency components). When represented in a matrix, those elements always appear in the same coordinates. DeMo, however, takes information from the top magnitude components, regardless of where they appear in the matrix. That allows the scheme to surface updates from anywhere in the frequency spectrum, rather than continually biasing towards information in fixed coordinates.
When we are ready to synchronize the nodes, we use an inverse discrete cosine transform to recover approximate gradient components, and use those approximated components to update the model parameters.
To enhance efficiency, the DCT basis matrices can be divided into chunks and pregenerated, which reduces the wall-clock time overhead for both compression and decompression. In practice, this overhead is less than 1% of the total training time.
At its core, DisTrO is expressed by the following weight update equation:
For a full description of the algorithm, see Algorithm 1 and the explanation in the paper.
PSYCHE'S UPDATES TO DEMO
In the Psyche codebase, we implemented several improvements to the original DeMo algorithm.
First, we added overlapped training so that a node no longer has to wait for all the updates from the previous step to download before starting the next step. While sharing DisTrO results from the previous step, they're already training on the next one. Because DisTrO results grow sub-linearly to model parameter size, as we apply DisTrO to larger models, the amount of wall-clock time spent training the next step will outpace the wall-clock time spent communicating the previous steps' DisTrO results. That means communication latency will, in theory, not be a bottleneck as we scale. This drastically improves GPU utilization and theoretically can make DisTrO set-ups as efficient as centralized set-ups.
Training over 3 steps using Overlapped DisTrO
| Apply Update | Generate Update | Witness Activity | |
|---|---|---|---|
| STEP 0 | skip | generate 0 | witness (dummy) |
| STEP 1 | skip | generate 1 | witness 0 |
| STEP 2 | apply 0 | generate 2 | witness 1 |
| STEP 3 | apply 1 | generate 3 | witness 2 |
| STEP 4 | apply 2 | skip | witness 3 |
| STEP 5 | apply 3 | skip | witness (dummy) |
Second, we further reduced the bandwidth of our previous implementation of DisTrO by "quantizing" the Discrete Cosine Transform of our momentums. As it turns out, simply communicating the sign of the DCT in a DisTrO result conveys all the information needed to recreate the correct momentum matrix and, therefore, the correct gradient updates. In other words, the magnitude of the DCT conveys practically no additional useful information. By just sending the sign (positive or negative, 1 or -1) without magnitude (as well as the indices of where in the matrix these signs apply), we compressed results by more than 3x. This compression is enabled for a given run whenever the flag quantize_1bit is on.
PSYCHE'S ARCHITECTURE
Psyche implements DisTrO in a Rust-based system with P2P networking that is designed to coordinate multiple runs at any given time.
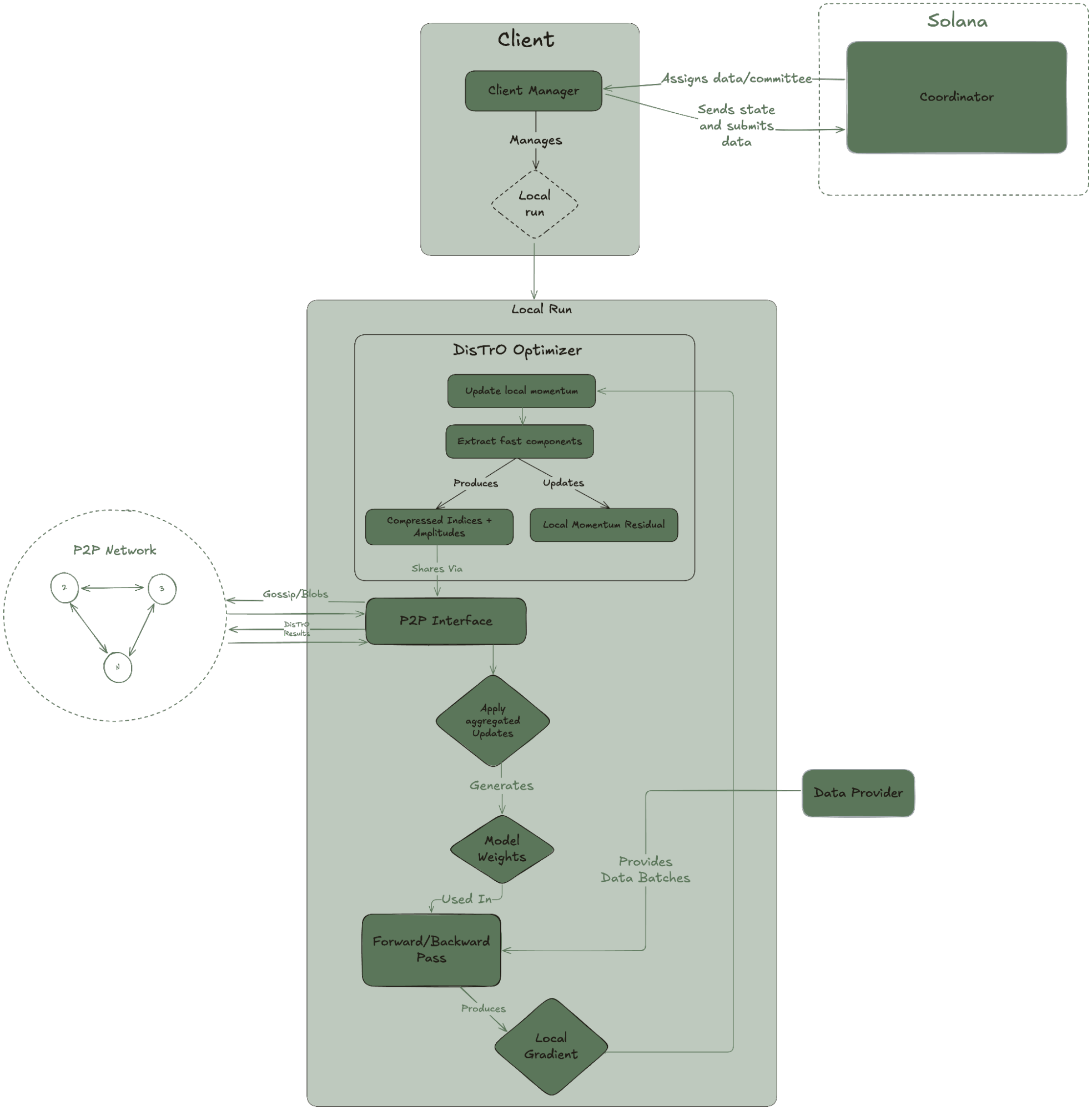
The Psyche architecture has three main actors:
COORDINATOR
The coordinator acts as an authority for the state of the training run and lives on-chain in a smart contract. The coordinator:
- Stores metadata about the run and the list of participants
- Handles the transition between states of a training run
- Provides randomness to determine assignments and witnesses
- Provides a point of synchronization between all the participants
CLIENTS
A client is a GPU node responsible for part of the training. Additionally, it may act as a witness or upload a checkpoint during the run. Clients perform three operations during a run:
- Training: Compute gradients, share them with other clients, and update the model's parameters
- Witnessing: Verify the liveness and correctness of other clients
- Verifying: Recompute and compare results with other participants to detect malicious actors
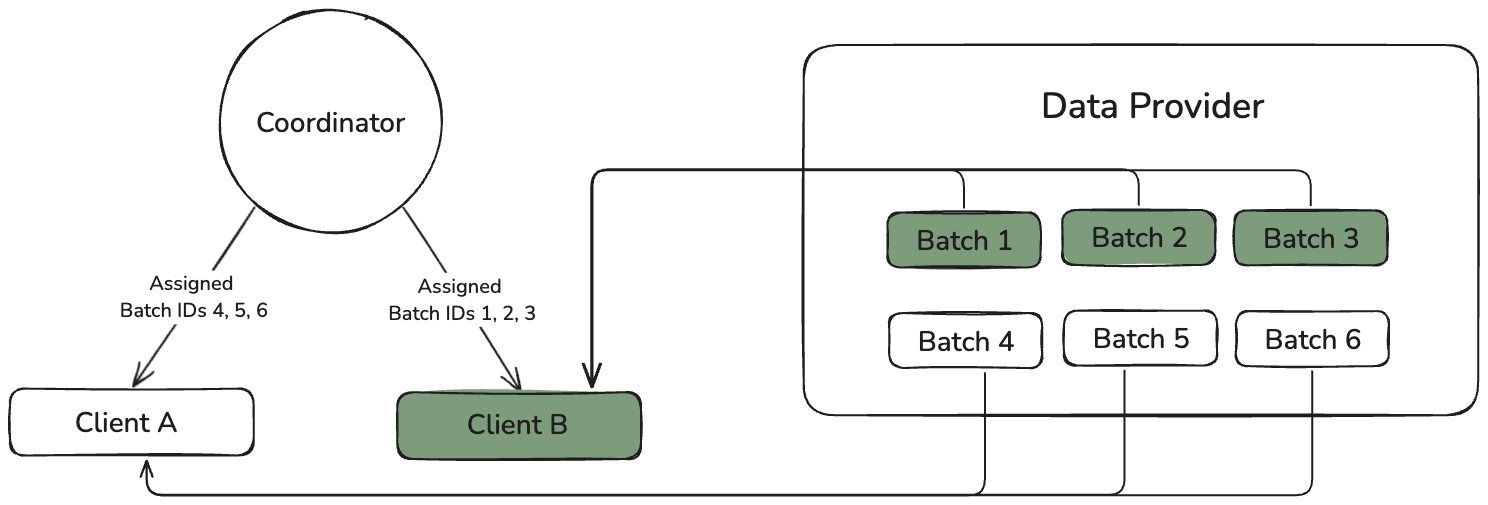
DATA PROVIDER
The Data Provider is responsible for providing the necessary data for training. It can be local (each client is responsible for their own copy of the training data) or an HTTP or TCP provider.
THE TRAINING RUN LIFECYCLE
A Training run in Psyche is composed of multiple "epochs". In this case, an epoch is a set of training steps (for example, 500 training steps) into which we break the whole training process (this definition differs from the one used in traditional ML parlance). During on-boarding, the run pauses briefly to allow new-entrants to download a checkpoint of the model.
We designed Psyche with epochs to reduce the opportunity cost for contributing compute, giving clients an opportunity to safely on-board and off-board. Compute providers can stop running Psyche on relatively short notice in favor of more lucrative opportunities, which should contribute to lowering the cost of training by encouraging otherwise idle GPUs to participate.
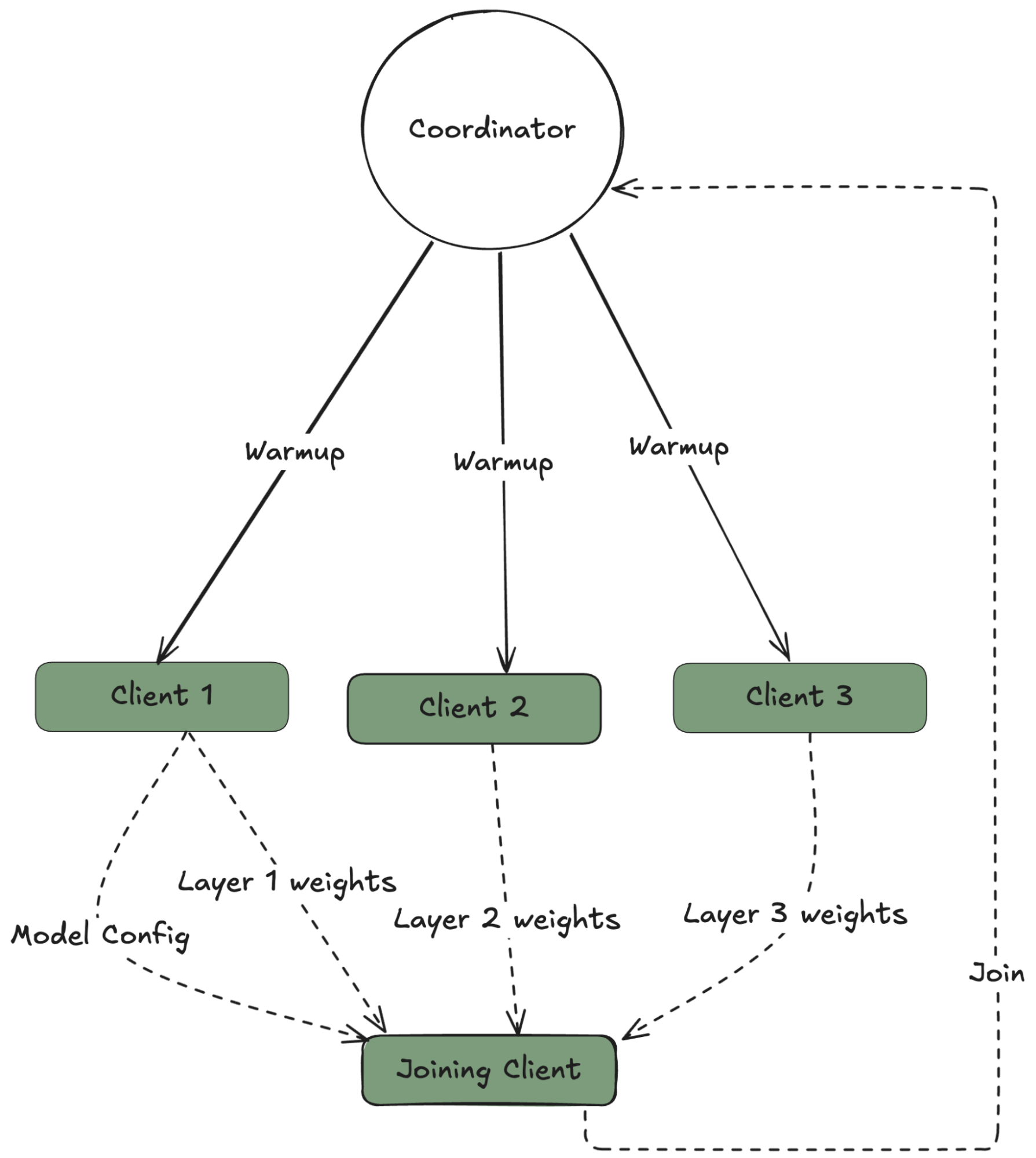
At the beginning of an epoch (which includes the beginning of a new run), new clients have two options for downloading the model:
-
 HuggingFace checkpoint A set of clients are responsible for uploading the information to HuggingFace after each epoch and sending the URL for this checkpoint to the coordinator.
HuggingFace checkpoint A set of clients are responsible for uploading the information to HuggingFace after each epoch and sending the URL for this checkpoint to the coordinator. -
P2P checkpoint Clients can get the latest parameters from available peers requesting a set of parameters for each layer from different clients.
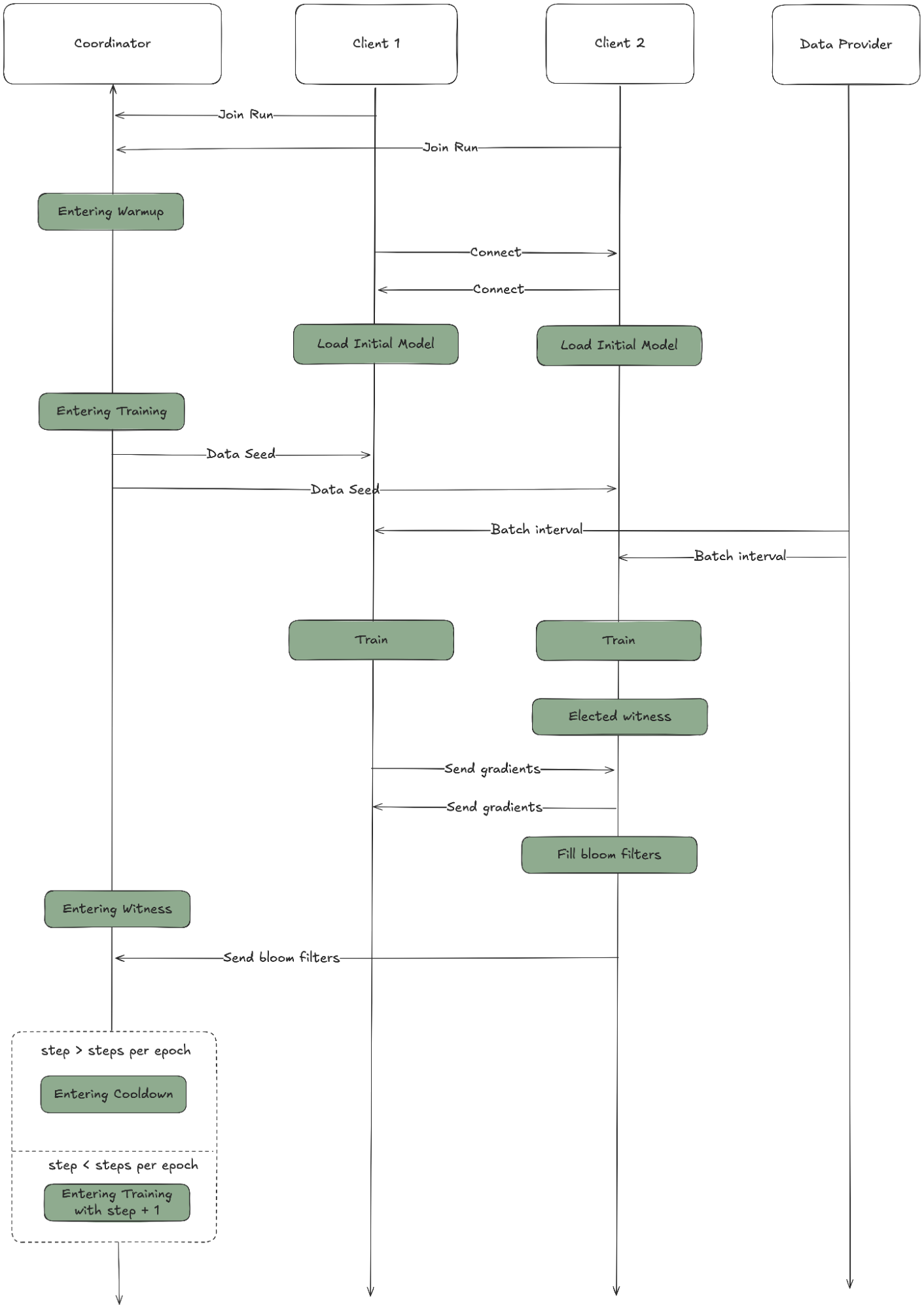
Once joined, an Epoch behaves as follows:
- Waiting for Members Phase: The coordinator waits until a minimum threshold of clients connects.
- Warmup Phase: Clients download and load the model. If a client disconnects and the number falls below the minimum, the process reverts to waiting.
- Training Phase: The coordinator provides a random seed to determine which training data to use. Clients fetch data, compute their portion of training, and share results with other clients.
- Witness Phase: Designated witnesses verify client activity, generating "witness proofs" (compressed via Bloom filters) and forwarding them to the coordinator.
-
Continuation or Cooldown: The protocol either
continues to the next training step or enters cooldown if:
- Participation drops below the minimum threshold
- The current step completes an epoch
- Witness quorum isn't achieved
- Cooldown Phase: Certain clients checkpoint the model before returning to the waiting phase.
P2P AND NETWORKING
To make networking easier for clients, we take advantage of UDP hole-punching, allowing nodes behind NAT or firewalls to directly connect to one another without manually coordinating ports. Hole-punching enables direct connections between peers behind firewalls by coordinating simultaneous connection attempts, creating temporary openings in firewalls that allow direct communication without requiring manual port forwarding or relay servers.
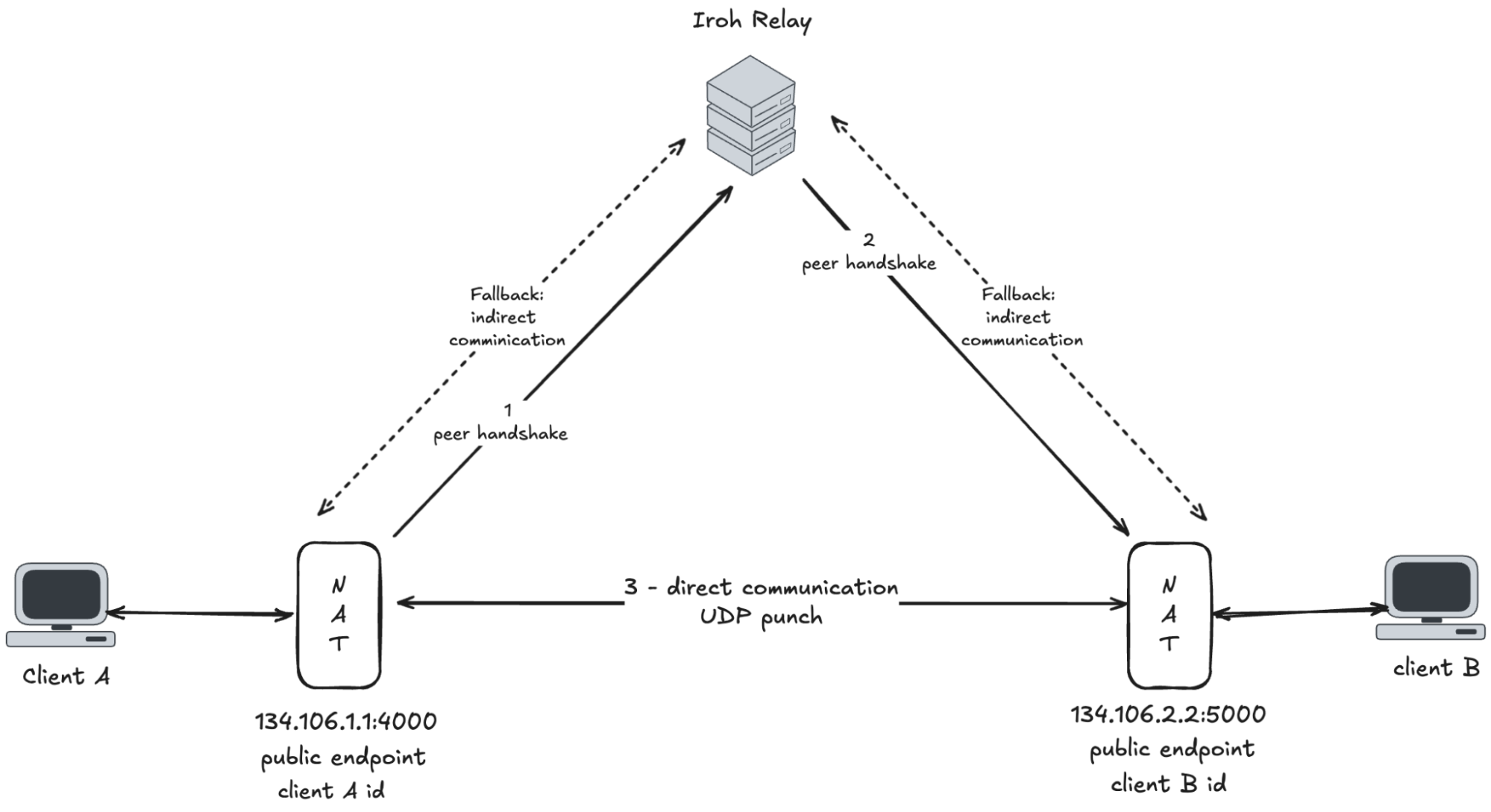
Psyche uses
Iroh
for its P2P networking. Applications using Iroh connect to peers using a
NodeId, a 32-byte
Ed25519
public key, instead of their IP address. This design decouples routing
from physical network addresses:
NodeIds are globally unique, self-generated, and remain
stable across network changes. Because they are cryptographic keys, all
connections can be end-to-end encrypted and authenticated by default
(each peer verifies the other's NodeId during the
handshake).
By default, Iroh attempts to establish direct peer-to-peer connections over UDP (using QUIC ) whenever possible and falls back to relays if necessary. This ensures that direct connections are established in around 90% of the cases (with the remainder handled via relays), higher than libp2p (70%) or BitTorrent's generic UDP hole punching (60-70%).
Moreover, Iroh can seamlessly switch between relay and direct mode on the fly. If network conditions change (say a node has one network interface drop, but another still works), Iroh will dynamically migrate the QUIC connection – using QUIC's connection migration capability – or revert to the relay as needed, without dropping the session. This makes connections highly reliable, surviving IP changes and network transitions transparently.
Psyche Nodes participating in a training run communicate metadata about
training results amongst themselves using
iroh-gossip
, a protocol based on
HyParView
and
PlumTree
, and include an iroh-blob ticket identifying a hash of a
binary blob containing the results. Nodes can then download the results
through the Iroh blobs protocol and continue with their training.
FAULT TOLERANCE AND ROBUSTNESS
We expect that during any run, nodes may not exit "gracefully" at the end of an epoch. During training, if a client does not receive data from another client, it sends a health check to the coordinator. If the coordinator sees sufficient negative health check messages from clients, it removes the node that crashed. Unresponsive nodes will no-longer receive their apportioned data from the run coordinator, and their data will be re-trained over.
We also avoid scenarios where too many nodes go offline by pausing and restarting epochs that will likely not complete in a reasonable amount of time.
BLOOM FILTERS FOR EFFICIENT VERIFICATION
Psyche uses bloom filters to efficiently check to make sure clients' DisTrO results are shared. Bloom filters are cheap data structures used to check for membership in a set. They occasionally yield false positives, meaning they will indicate an element is in the set when it isn't, but we accept that potential in a tradeoff for efficiency (as opposed to something more definitive like a merkle tree).
Bloom filters basically create an array of bits initialized to 0. Then, when we see a new item that we want to add to the set, we run a number of different hashing functions on that item and set the index at the resulting hash functions to 1. So, when checking whether an item is in the set, we just need to run those hashing functions. If any one of them returns 0 at that index, we can stop checking and know for sure that the item isn't in the set. If the item passes all of our tests, we're pretty sure it's in the set.
PSYCHE 40B: CONSILIENCE
Our first run on Psyche will pretrain a 40B parameter model using the Multi-head Latent Attention (MLA) architecture across 20T tokens, which we're naming Consilience. This represents the largest pretraining run conducted over the internet to date, surpassing previous iterations that trained smaller models on much fewer data tokens.
We designed this model to be powerful and accessible in a very useful size-class. At 40B parameters, it's compact enough to train on a single H/DGX and run on a 3090 GPU, yet capable enough to serve as a foundation for advanced reasoning models and creative applications.
Although we're utilizing Deepseek's V3 MLA architecture, we've opted for a dense model rather than a Mixture-of-Experts. MLA creates a hierarchy of attention mechanisms that process input data at varying levels of abstraction. Recent research has demonstrated that MLA can fully represent GQA (the architecture used in Llama), while GQA cannot represent MLA—proving that MLA is strictly more expressive than its counterpart.
Additionally, MLA's efficient attention mechanism reduces the size of query-key-value (QKV) projection matrices, creating computational "room" to either deepen the network with additional layers or widen existing layers.
For training data, we combined FineWeb (14T), FineWeb-2 with some less common languages removed (4T), and The Stack V2 (~.2T, upsampled to 1T tokens). We chose these datasets over more specialized pre-training datasets that aim to purely increase benchmark performance. Our goal with Consilience is to make a true "base" model -- one representative of the entirety of the creative output of humanity, and not merely trying to win the benchmaxxing game.
We're training this model continuously without a final data "annealing" step. While annealing helps base models respond more accurately to benchmarks and improves usability, it may potentially constrain creativity and interesting behaviors. Our solution is to simply release both versions: the raw, un-annealed base model first, followed by an annealed version to aid in usability.
VERIFICATION APPROACHES AND NEXT STEPS
We've developed a theoretical model for verification, but a practical implementation is still an open problem.
Our current verification efforts revolve around duplicating work and checking whether nodes' DisTrO results fall within an expected range. Bitwise verification in Psyche is difficult (but not impossible) for several reasons. Firstly, training itself is non-deterministic because there are variations in how floating point operations are calculated. Two of the same accelerators might not produce exactly the same MatMul results given the same input data, and adding three floats in a different order when using tensor parallelism will give you slightly different values. These variations repeat billions of times, causing accumulation of floating-point error.
Secondly, DisTrO introduces additional variability. DisTrO results are compressions, and the information chosen by the method to send to other nodes depends somewhat on a node's internal view of the model. Models on different nodes will vary slightly, given that we never complete a full all-reduce or averaging on uncompressed data at any step. However, these variations are so slight that, practically, one can consider each node's model as the same. This similarity is inherent to the fact that DisTrO works.
If we know models are practically quite similar, we can intuit that two nodes on the network given the same data to train over will produce similar results. The difficulty lies in striking the balance in how we judge similarity. We rely on empirical tests to discover the "normal" range of variability among "honest" nodes across several metrics:
- Jaccard index - The Jaccard index measures the overlap of elements between two samples, but it could be exploited by shuffling elements within the sets. By itself, it doesn't capture changes in the order or magnitude of the parameters, which is why additional metrics are needed.
- Manhattan geometry - Manhattan geometry captures the total difference in values across the samples. However, attackers might tweak parameters so that these differences cancel each other out, leaving the score unchanged. This limitation necessitates other metrics to ensure comprehensive similarity.
- Hamming distance - Hamming distance counts exact differences at specific positions, but on its own, it might not detect a scenario where similar but shuffled sets have minimal positional changes. Therefore, it works in conjunction with the other metrics to ensure a robust similarity check.
Together, these metrics complement each other by addressing the individual weaknesses of each approach, making it significantly harder for an attacker to manipulate the parameters without detection.
If we are too strict on what's acceptable, we will wind up with false positives, but if we are too lax, we will open training to subtle and consistent influence by attackers. The amount by which an attacker can systematically influence a training run by slightly changing otherwise-"correct" results is also a matter that demands empirical study.
THE FUTURE OF AI DEVELOPMENT
Psyche represents more than just a technical innovation—it's a fundamental shift in how AI development can occur:
-
Democratization Enabling broader participation in AI development beyond large corporations.
-
Resource Efficiency Utilizing otherwise idle computing resources worldwide.
-
Alignment Creating models that aren't controlled by any single entity.
-
Experimentation Dramatically lowering the financial barriers to AI research.
By distributing training and leveraging DisTrO's efficient communication, Psyche makes it possible to train models at a fraction of the cost of centralized approaches, all while maintaining training quality.
What we would like to see from this release is a massive expansion in experimentation during training. We imagine a (not-distant) future where diverse sets of researchers can test ideas in parallel, and when those researchers discover something promising, Psyche can meaningfully scale the effort.
We invite you to join us in this journey to democratize AI development. Check out our code on GitHub and consider contributing to the project.
Read more about Psyche
What we would like to see from this release is a massive expansion in experimentation during training. We imagine a (not-distant) future where diverse sets of researchers can test ideas in parallel, and when those researchers discover something promising, Psyche can meaningfully scale the effort.
See the Docs