
Today we’re releasing Hermes 4.3 (🤗 Hugging Face), an update to our flagship Hermes series of models. Hermes 4.3 was trained with an extended context length (up to 512K) and nearly matches (and in some cases exceeds) the performance of Hermes 4 70B at half the parameter cost. Based on Seed-OSS-36B-Base, Hermes 4.3 is an excellent shape for consumer local inference or enterprise self-deployment. The GGUFs comfortably sit in the VRAM of off-the-shelf GPUs, offering a private, powerful, neutrally-aligned model to everyone.
Hermes 4.3 is our first production model post-trained entirely on the Psyche network, our distributed training network that uses the DisTrO optimizer to efficiently communicate between training nodes spread out through data centers over the open internet and secured by the consensus of the Solana blockchain. By enabling nodes throughout the world to collaborate on a single training run, Psyche can dramatically reduce the cost of training frontier level models, leveling the playing field for open source AI model developers.
Although we’ve performed extensive scientific research on DisTrO and its implementation in Psyche, we decided to verify its effectiveness for production workloads by training Hermes 4.3 both on Psyche and via the traditional centralized approach. As outlined in the Hermes 4 Technical Report, we used our custom version of Torchitan to train Hermes 4.3 following the same recipe as Hermes 4 (FSDP+AdamW). We then trained the model a second time on Psyche (TP+DisTrO). Given the extended context length and increased training set size, the Hermes 4.3 training run was twice as large as Hermes 4.
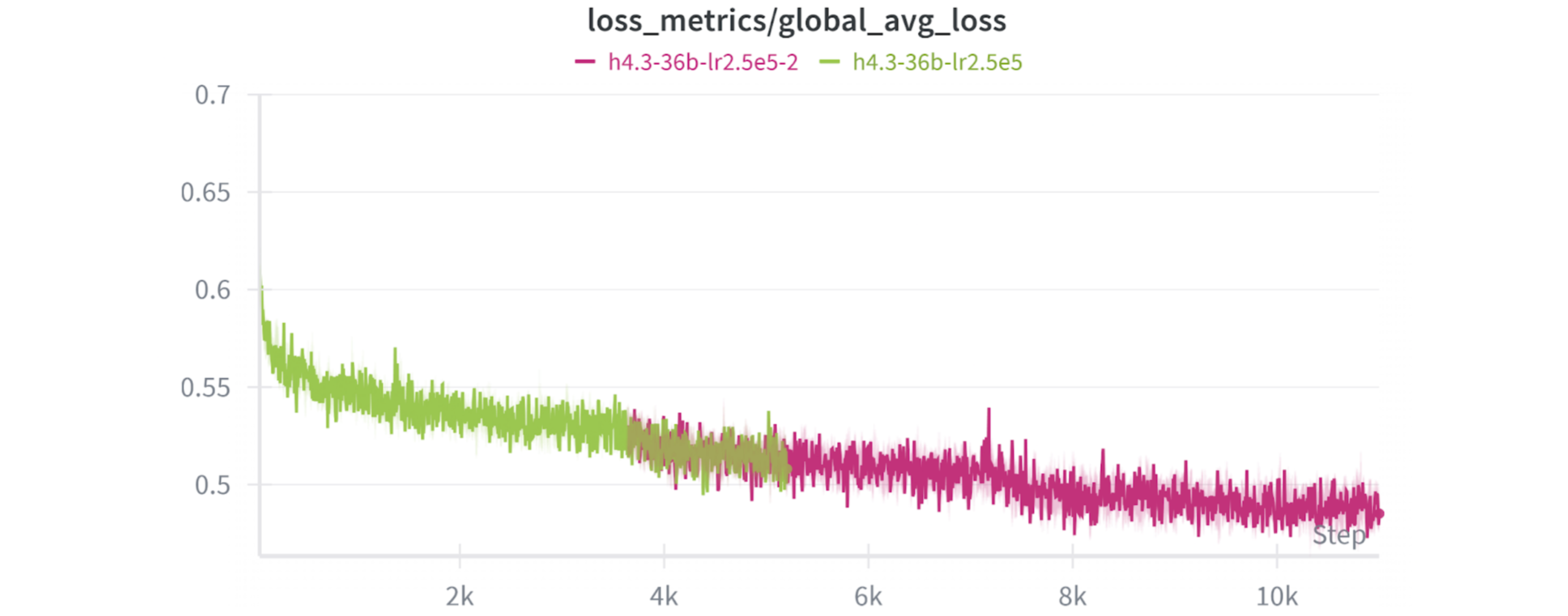
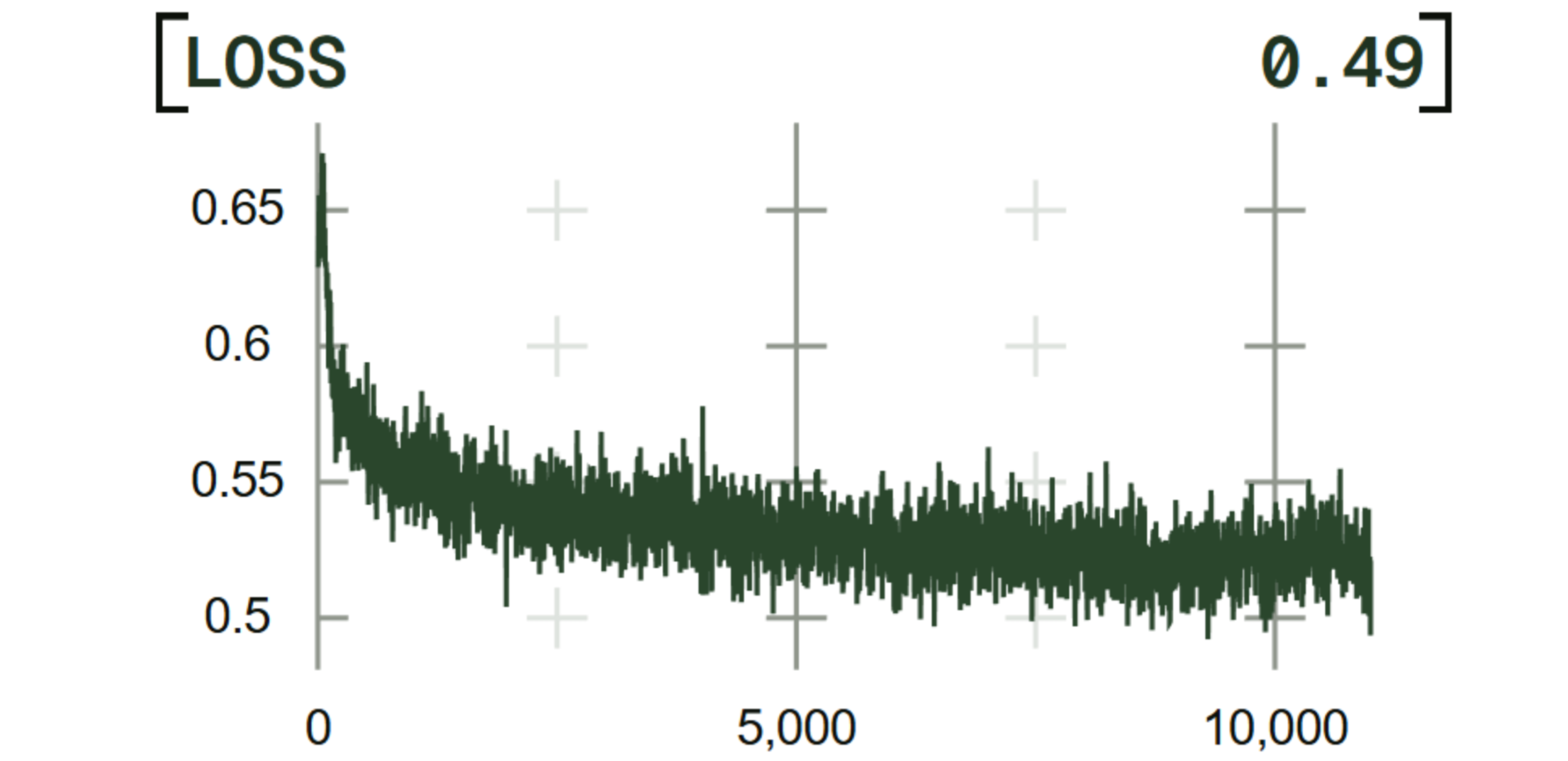
The training run proved stable throughout, averaging 144k tokens/second spread across 24 Psyche nodes. Using DisTro’s overlapped collective strategy, the entirety of the P2P communications were hidden by the training time, effectively achieving equivalent throughput to traditional, centralized training. Under the hood, Psyche uses a dual L1-P2P networking model where consensus state is managed by a smart contract on the Solana blockchain while training gradients are communicated out-of-band through a custom mesh P2P network.

The Psyche trained version of Hermes 4.3 outperformed the traditional centralized version on a suite of downstream tasks. Although previous runs had produced similar results, it was a confirming signal that Psyche is up to the task of training production models. Hermes 4.3 achieves SOTA on RefusalBench across all popular closed and open models in being helpful and aligned to the user’s values. For transparency we are publishing the full set of evaluation responses and scorings. In addition we are releasing the centrally trained version (🤗 Model, Evals) as a research artifact (you’re welcome @xl8harder).
To learn more about Psyche, check out the live dashboard or the code on GitHub. You can also see all transactions live on Solana on any block explorer (contract address).
We pride ourselves on Hermes going beyond standard math and coding benchmarks (which we admit are easily gamed) and giving the user the broadest agency in exploration. Enjoy, Hermes 4.3 36B:
